Difference between COUNT (1), COUNT (*) and COUNT(COLUMN_NAME)
COUNT () is a function in SQL Server counts the number of rows. This method accepts only on parameter. Though it is a simple function, it creates a bit confusion based on the parameters (*, 1 and COLUM_NAME).
You might have seen the COUNT () function has been used in the below formats
COUNT (1)
COUNT (*)
COUNT(COLUMN_NAME)
COUNT(DISTINCT(COLUMN_NAME)
To demonstrate these differences, let us create a table as below
CREATE TABLE [dbo].[TestCount]
(
ID INT,
[FirstName] VARCHAR(100)
)
Then execute the below script to insert 1300000 records
DECLARE @i INT =1
set nocount on;
WHILE(@i <=1300000)
BEGIN
INSERT INTO TestCount (Id,FirstName)
VALUES (@i,'Test -'+CAST(@i as VARCHAR(100)))
set @i+=1;
END
Let us go ahead and execute the below query
select count(*) from TestCountIf we look at the execution plan, we can see that it that was a Table scan
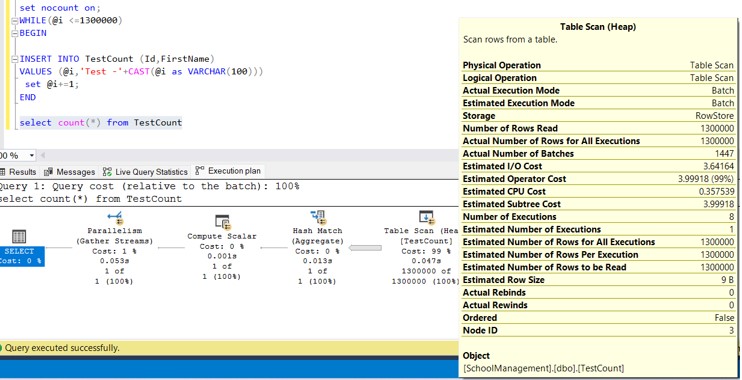
Now let us go ahead and create a Primary Key constraint on this table. To Create a primary key, we need to alter the column “ID” to set it as non-nullable.
Execute the below script
ALTER TABLE TestCount
ALTER COLUMN ID INT NOT NULL;
Then execute the below script
ALTER TABLE TestCount
ADD CONSTRAINT PK_TestCount PRIMARY KEY (ID);
Now execute the below query and see the execution plan
select count(*) from TestCount
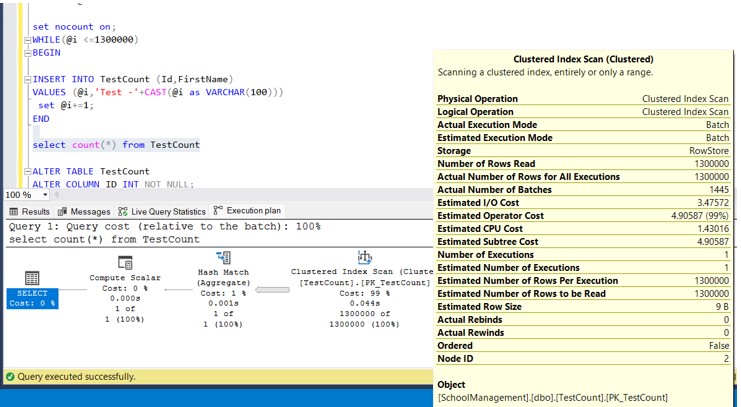
Now the scan become Clustered Index scan.
Now let us go ahead and execute the below script
select count(1) from TestCount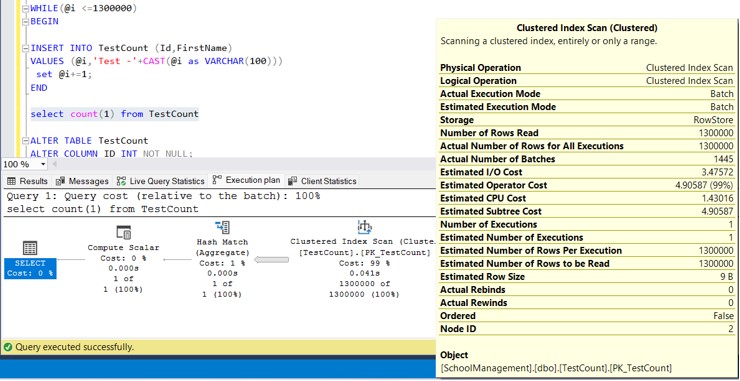
Still, we can see that Clustered Index scan on Execution Plan
Now execute below query and see the Execution plan
select count(FirstName) from TestCount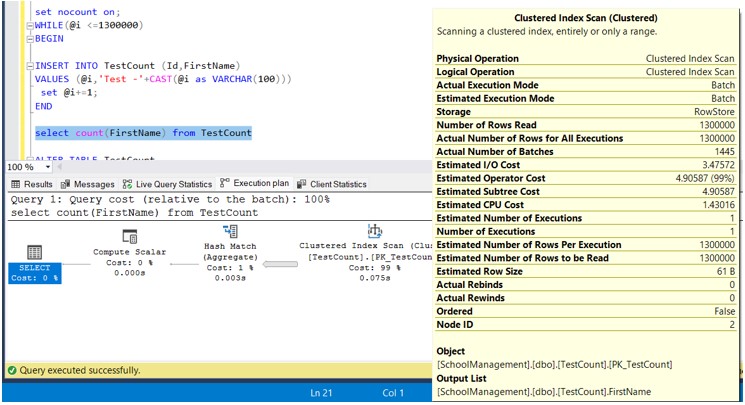
Still, we can see that the Clustered Index scan has been performed.
Now let us go ahead and create a non-clustered index as below
CREATE NONCLUSTERED INDEX IX_TestCount_FirstName
ON TestCount(FirstName)
Then execute the below query and see the execution plan
select count(FirstName) from TestCount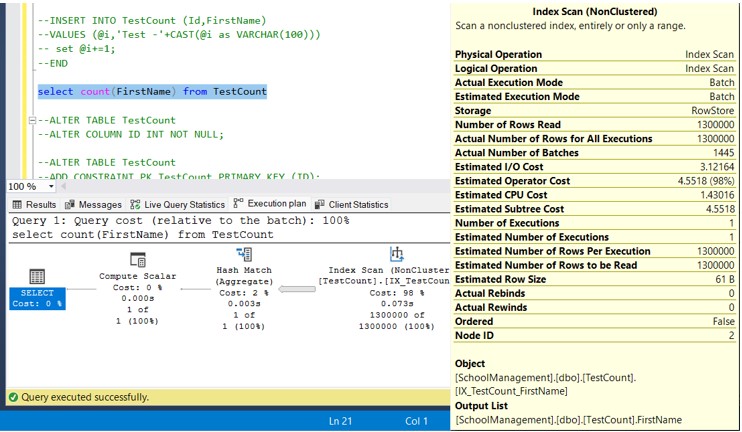
This time, Index scan has been performed and the non-clustered index has been considered. If you try to execute Count (*) or Count (1) or Count (ID), we will get the same execution plan with non-clustered index scan. I leave these executions to you to check